-
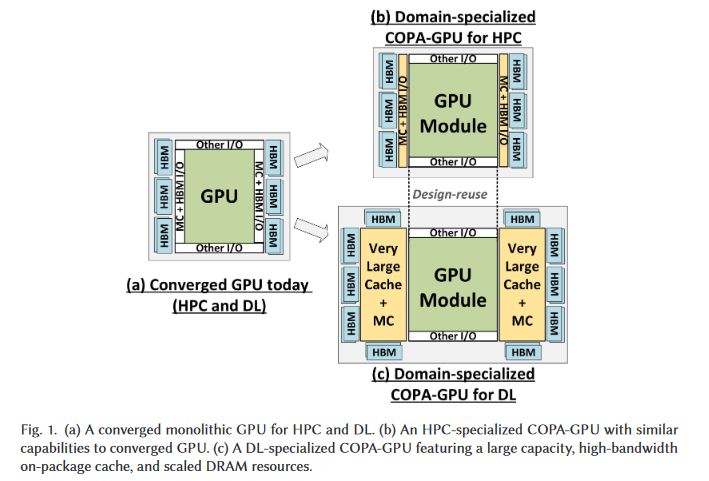
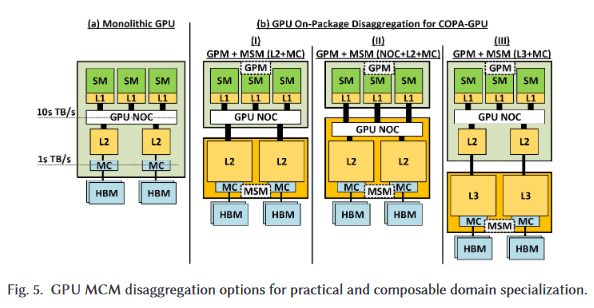
Nvidia Data Center GPU MCM Approach: Composable On-Package Architecture (COPA) Divergence of HPC and DL GPUs by modifying I/O and cache, depending on the workload, using chiplets. (1/x)Permalink On twitter.com
 ♻️ 9 Retweets
❤️ 48 Favorites
Mood 0
♻️ 9 Retweets
❤️ 48 Favorites
Mood 0
-
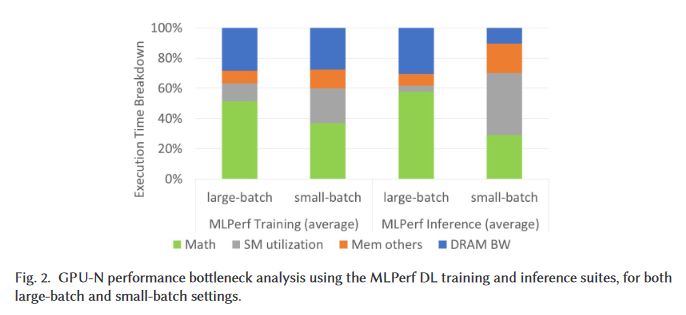
DL Bottlenecks (2/x)Permalink On twitter.com
❤️ 6 Favorites
Mood 0
-
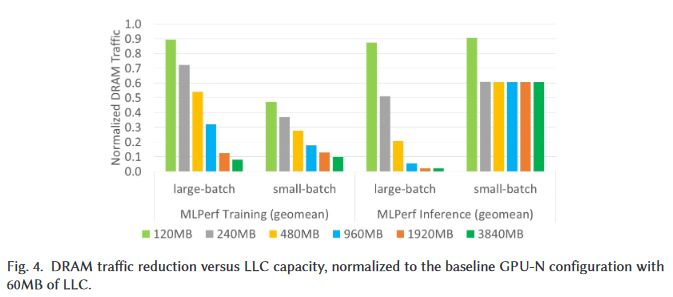
Ballooning LLC Requirements for DL Workloads (3/x)Permalink On twitter.com
❤️ 5 Favorites
Mood 0
-
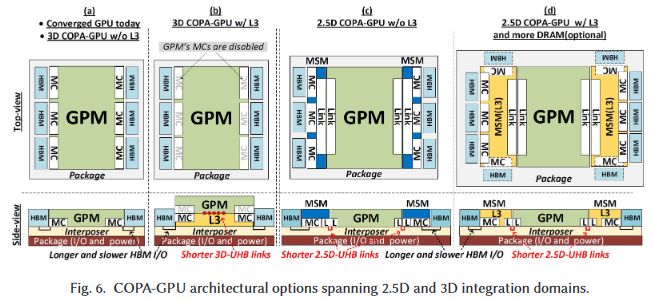
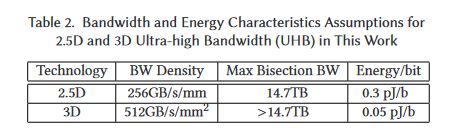
Bandwidth and Efficiency of 2.5D and 3D Packaging 28.7 mm² of silicon area is used for 14.7 TB/s with 3.5D Packaging. Conservative Estimate of 960 MB L3 in 826 mm² (4/x)Permalink On twitter.com
❤️ 8 Favorites
Mood 0
-
Effect of increasing BW in DL and HPC Workloads (5/x)Permalink On twitter.com
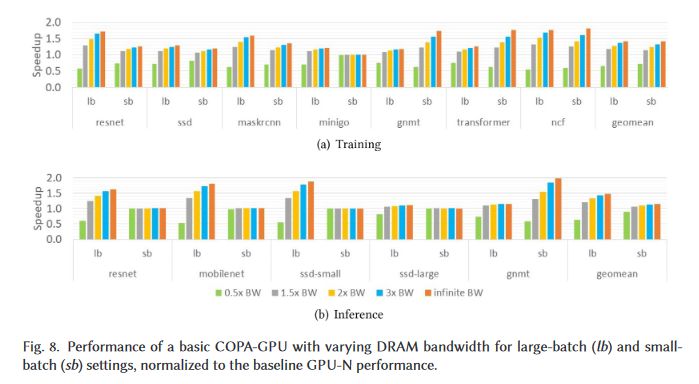
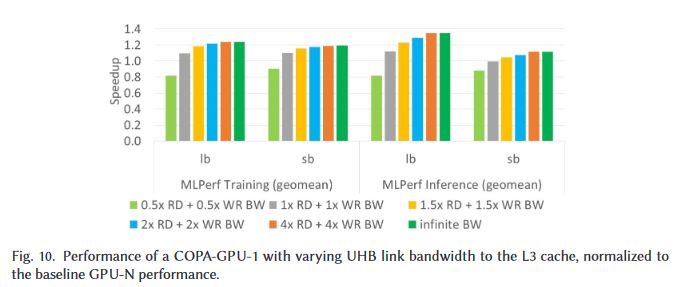
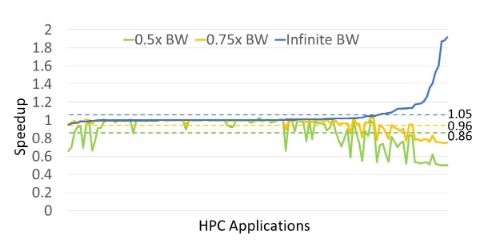 ❤️ 2 Favorites
Mood 0
❤️ 2 Favorites
Mood 0
-
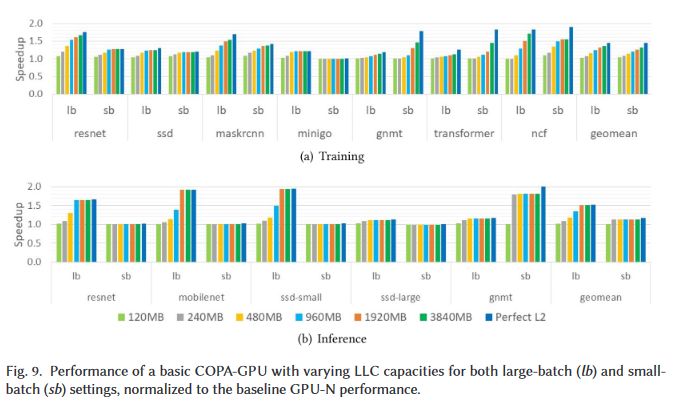
Effect of various COPA-GPUs in DL Workloads (6/x)Permalink On twitter.com
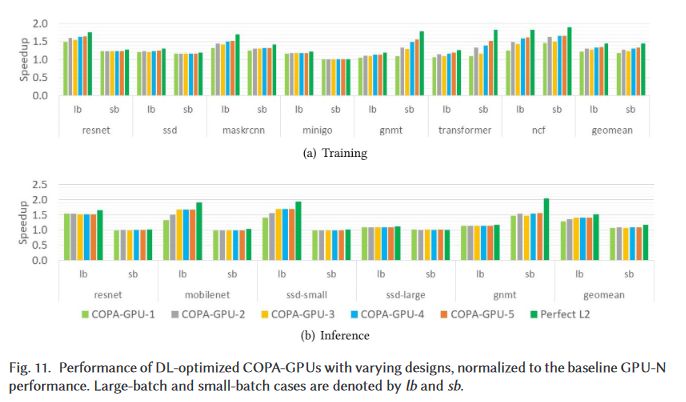 ❤️ 2 Favorites
Mood 0
❤️ 2 Favorites
Mood 0
-
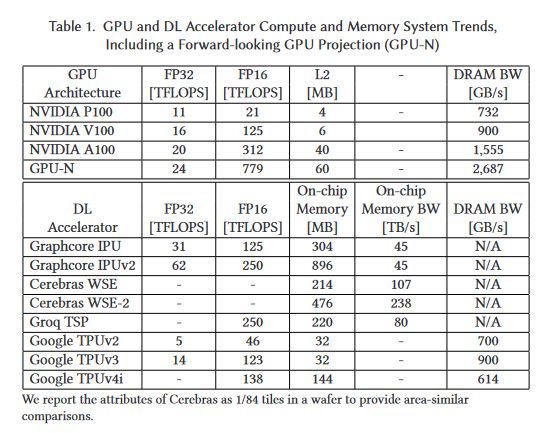
The mysterious GPU-N Note: All benchmarks are run in NVArchSim, simulating GPU-N High Accuracy for MLPerf Workloads Comparison with other DL ASICs (7/x)On twitter.com
 ♻️ 1 Retweets
❤️ 7 Favorites
Mood 0
♻️ 1 Retweets
❤️ 7 Favorites
Mood 0
-
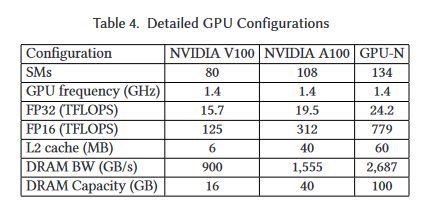
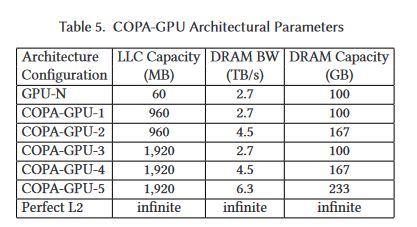
GPU-N and COPA-GPU Configurations SMs: 134 Frequency: 1.4 GHz TFLOPs: 24.2 FP32, 779 FP16 L2: 60 MiB (to 1920 MiB) DRAM Bandwidth: 2.687 TB/s (to 6.3 TB/s) DRAM Capacity: 100 GiB (to 233 GiB) (8/x)Permalink On twitter.com
 ♻️ 1 Retweets
❤️ 6 Favorites
Mood 0
♻️ 1 Retweets
❤️ 6 Favorites
Mood 0
-
Now, it's time for my favourite, speculation. I believe GPU-N is a single-die GH100, with a total of 144 SMs, with 134 enabled. It seems to have 6144b HBM2e @ 3.5 Gb/s. GPU-N is the HPC version of the GPU, while the various COPA-GPUs (CG) are DL-optimised. (9/x)Permalink On twitter.com
♻️ 1 Retweets
❤️ 6 Favorites
Mood +2 🙂
-
CG-1 and CG-3 have 6144b HBM2e CG-2 and CG-4 have 12288b HBM2e CG-5 has 14336b HBM2e I don't expect all of these CGs to exist, since it would require both 2.5D and 3D packaging capable GH100 dies. (10/x)Permalink On twitter.com
❤️ 6 Favorites
Mood +1 🙂
-
As I was worried, it seems Nvidia has decided to focus on DL performance, given the FP32 scaling is only due to increased SM count, and presumably FP64 (HPC) as well. This isn't really conducive to the 3x performance rumour. (11/x)Permalink On twitter.com
❤️ 5 Favorites
Mood -2 🙁
-
Source: GPU Domain Specialization via Composable On-Package Architecture By: Nvidia, USA (12/x) dl.acm.org/doi/10.1145/3484505Permalink On twitter.com
❤️ 8 Favorites
Mood 0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}